Migrating to Pelican - Extracting WordPress Data
I've been slowly working on migrating this site to Pelican.1 I have crossed the first major hurdle, which is getting my posts and meta data out of WordPress and into MultiMarkdown files.
Pelican
There are plenty of other sites that describe what Pelican is and how it works. Here's a brief synopsis: Pelican is a static blogging system that generates a blog structure and each post from plain text files.
There are plenty of other static blogging options like Octopress or Jekyll. I chose Pelican, because I liked the Jinja templating system and I like working in Python.
I like static blog systems because I can understand all of the pieces without much effort. It's HTML served up plain and simple. It's fast and light weight. It's easily portable to a new server by copying the root directory. There's no database to worry about. There are no vulnerabilities to patch every few months. But what I really like about a static blog, is that I can just write in MultiMarkdown and post through FTP or Dropbox.2 There's no API to push content around.
The downside is that most of the documentation for static blogging systems expect a clean installation or migration of very simple content. There are few "plugins" available out of the box. Instead most tweaks are done by writing new modules. There are few themes that can be dropped in to change the site.
Extracting WordPress Data
Pelican provides a built-in option to convert a WordPress XML export or feed directly into a folder full of individual Markdown or reStructured text files. I'm sure it works for someone, but it was fraught with error messages for me. After massaging the XML file a bit I finally finished a successful run just to find that the exports did not properly interpret my footnotes and many code blocks. As any self loathing geek would do, I decided to build my own export tools.
Brett Terpstra was kind enough to provide some custom Ruby tools he made to export WordPress to Jekyll. His code comes by way of Mihail Szablocs and I am thankful to both of them. They provided enough of a foundation, that I decided to build my own custom exporter in Python. Brett's scripts extracted the WordPress content directly from the MySQL database rather than rely on the XML export provided by WordPress.3 I decided to do something similar.
The first step is to extract all of the WordPress posts in Sequel Pro.4 I really like Sequel Pro. It's a great app that is donation-ware but works like a high-end app.
Warning
This directly interacts with the WordPress database. I'd suggest having a good backup before doing this. I'd also suggest anyone doing this have a modicum of knowledge about SQL. Selects are good. Updates are bad.
This SQL gets the post title, date, id, author, original URL and any link that may have been used as a linked-list post.
:::SQL
select ps.post_title, ps.post_name, ps.post_date, ps.post_content, ps.post_excerpt, ps.ID, ps.guid, ll.meta_value
from wp_posts ps
left outer join
(select meta_id, post_id, meta_value
from wp_postmeta
where meta_key = 'linked_list_url') ll on ps.ID = ll.post_id
where ps.post_status = 'publish' and ps.post_type = 'post'
In Sequel Pro, I then export this data set as a Plain Schema XML. The XML format must be set to the Plain Schema for the script below to work properly.
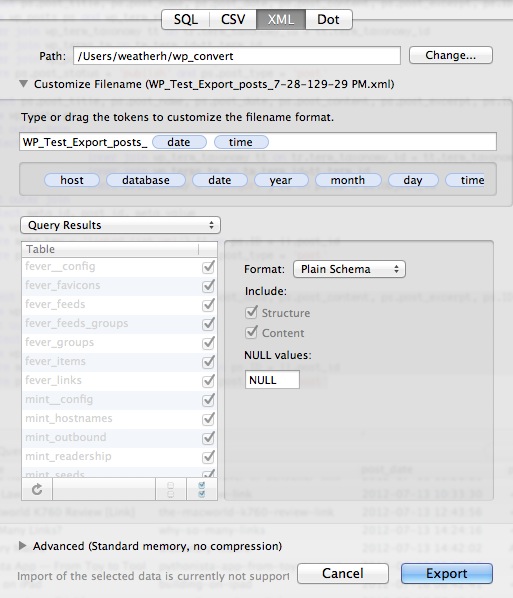
I also wanted to get all of the post categories. I don't use WordPress tags. I use categories only. In Pelican, I wanted to migrate those to tags. I decided to create a second export of just the tags and the post IDs. Here's the SQL I used for that.
:::SQL
select tm.term_id,tm.name, tr.object_id from wp_term_relationships tr
inner join wp_term_taxonomy tt on tr.term_taxonomy_id = tt.term_taxonomy_id
inner join wp_terms tm on tm.term_id=tt.term_id
where tt.taxonomy = 'category'
I exported this as a generic XML file. At this point I have two XML files. One file is all of the post content and the other contains the post categories.
String Encoding Be Damned
The next step was to massage the XML files a bit to make the Python script easier. Experience has shown me that no significantly-complex utf-8 encoded text file will only have Unicode characters. Rather than write a bunch of encoders/decoders it is much easier to just open the file in BBEdit and do some basic fixes.5 I used the Zap-gremlins option in BBEdit to get rid of odd control characters. It's worth keeping the file loaded in BBEdit during processing.
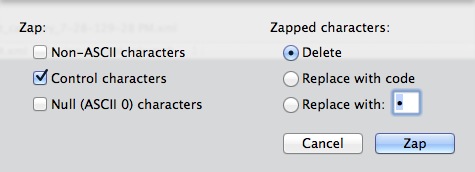
There will be Unicode errors to address individually.
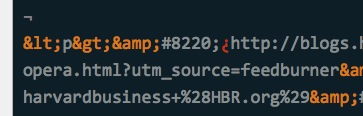
I also reduced the complexity of the XML by removing the extraneous info output by Sequel Pro. It's not necessary but sometimes one delete key can save many lines of Python code.6
XML to Pseudo Markdown
I tried several mechanisms to reliably convert all of my HTML to MultiMarkdown without success. Footnotes were particularly troublesome. Since most of my favorite bits are in the footnotes, I didn't want to sacrifice any of them.
Markdown can have HTML embedded so I went with the foolproof conversion. I kept the HTML of the post and just prepended the MultiMarkdown headers required by Pelican. It's not fundamentalist Markdown. I call it progressive and good enough.
XML Processing
This is a bit of Python that will read in the two specified XML export files. It will then read the XML and generate one MultiMarkdown file for every post. Each file will contain a header of the meta data that can be used by Pelican.
:::python
from lxml import etree
from lxml import objectify
import os
import sys
import markdown
# File that holds the XML of all of the posts
filePath = "/Users/weatherh/wp_convert/ZapWP_Test_Export_posts_7-28-129-30 PM.xml"
# File that holds the XML of all of the categories
catFilePath = "/Users/weatherh/wp_convert/ZapWP_Test_Export_category_7-28-129-28 PM.xml"
parser = etree.XMLParser(remove_blank_text=True)
#lookup = objectify.ObjectifyElementClassLookup()
parser.setElementClassLookup(lookup)
# Tree object for the XML of WP Posts. This is a file reader too. Very convenient.
catTree = objectify.parse(catFilePath)
# Get the root of the category tree object
catRoot = catTree.getroot()
# Set the root of the WP Post tree
tree = objectify.parse(filePath)
root = tree.getroot()
# Loop over all of the rows in the XML to get the posts
for post in root.findall('row'):
md = markdown.Markdown(extensions = ['extra', 'meta'])
postTitle = post.find('post_title')
postName = post.find('post_name')
postDate = post.find('post_date')
postContent = post.find('post_content')
postGUID = post.find('guid')
postID = post.find('ID')
postLink = post.find('meta_value')
postHeader = 'title: '+postTitle+'\n'+'name: '+str(postName)+'\n'+'date: '+str(postDate)+'\n'+'guid: '+str(postGUID)+'\n'+'postID: '+str(postID)
if postLink != 'NULL':
postHeader = postHeader+'\n'+'link: '+str(postLink)
postCategory = []
## Get Categories for the current post ##
for category in catRoot.findall('row'):
if category.find('object_id') == postID:
postCatString = category.find('name')
postCategory.append(str(postCatString))
# We need the categories in a series of tab endented lines
allCategoryList = "\n\t".join(postCategory)
## Convert WP Categories to Tags ##
postHeader = postHeader+'\n'+'tags: '+allCategoryList
fullPost = postHeader+'\n\n\n'+postContent
f = open('/Users/weatherh/wp_convert/content/'+str(postName)+'.md', 'w')
# Write all of the files. Damn I hate string encoding with a passion.
f.write(fullPost.encode('utf8', 'replace'))
f.close()
The result of this madness, is a folder full of pseudo-Markdown.7
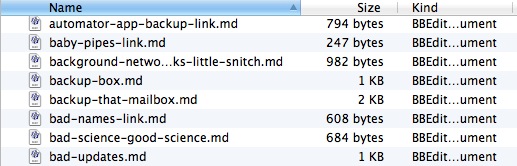
Each file contains a properly formatted MultiMarkdown header, which Pelican will convert to post properties.
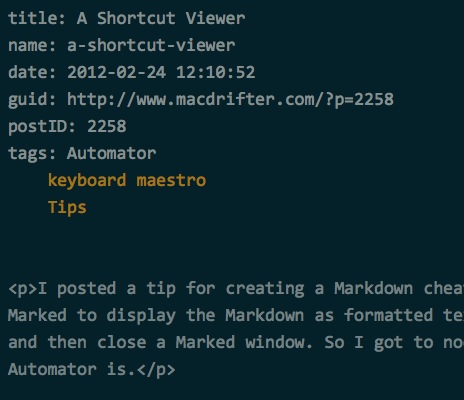
With this bolus of posts in hand, it's one terminal command to generate an entire Pelican static blog site that contains all of my old posts from Macdrifter. But I'll save that for another day.8
-
It's slow because there is a crap load of stuff I don't know and barely understand. It's also not how I make a living so it's low on my priority list. This project may never bear fruit other than ceasing my bitching about WordPress. ↩
-
Yes, I already have a system like that for WordPress. It's a hack that requires Dropbox and a Mac. ↩
-
Someone with superior patience could use the XML provided by a WordPress export, but that beast is too ugly for me to stare at. ↩
-
It's ugly and brutal but it gets the job done. Like an ape bending a twig to fish for termites, not all of my tools need to be pretty. Sometimes they just need to fish out a damn insect. ↩
-
BBEdit is one of the only text editors that can open a 254MB XML file in a split second and provide smooth scrolling. It's a marvel of engineering. Even Find-and-Replace is lighting fast. ↩
-
Usually one delete key is what it takes to fix many lines of my Python code. ↩
-
I call it "pseudo" because I typically do not think of Markdown as a bunch of HTML with a MultiMarkdown header. Real Markdown should contain as little HTML as possible. That's what the processor is for. ↩
-
I'm not trolling for clicks. This is very much a work in progress. And by progress, I mean just hours ago I finished this script. ↩