Automator Action to Open Files by Markdown Meta Data
I often use MultiMarkdown headers with my plain text files. I've found the headers can be quite useful in some contexts. For example, my Hazel rule for processing files based on a "tags" field.
But I've found it irritating that I can include such a large variety of data in the header but I can not really use it to find file when I need them. So I sat down and scratched this irritating itch. I made an Automator work flow that finds files in my Notes directory that have a matching "tags" field.
This is a typical MultiMarkdown header I use:
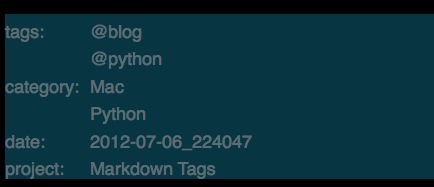
The Workflow
1. Trigger the Automator with Keyboard Maestro
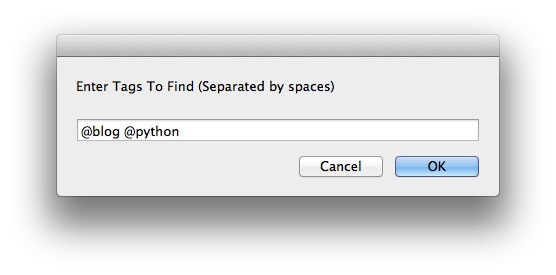
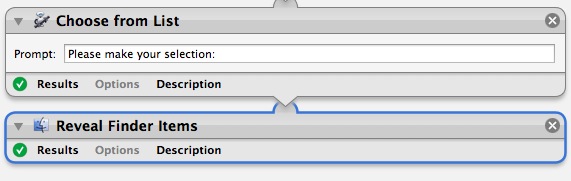
2. Get a popup asking for the tags to match:
3. I get back a list of files that match
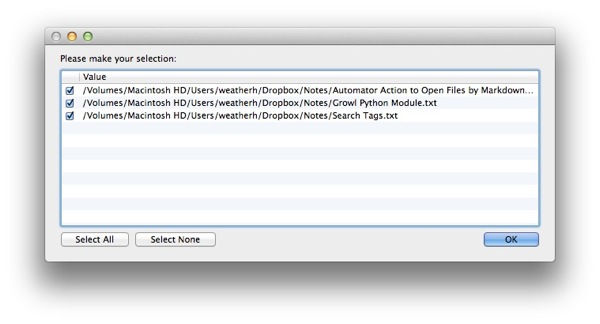
4. I select the files I'm interested in and click ok. The files open in a text editor (in this case, Sublime Text 2)
It's clunky, but it's a start.
The Automator Workflow
Here's how the Automator workflow is put together. The main purpose of the Automator workflow is to provide two pop-up windows. One window asks for the tags to search. The second window shows the files that match.
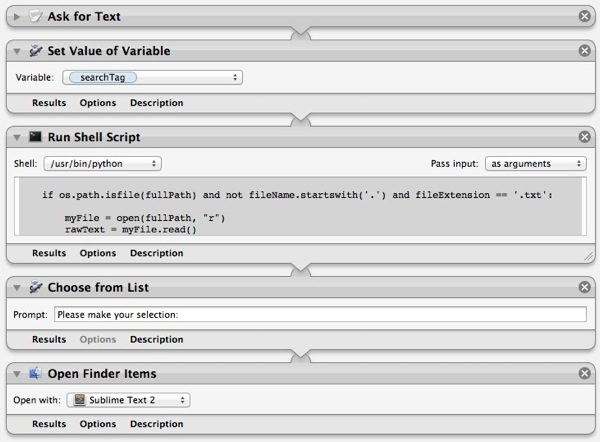
The Script
The meat of the workflow is the Shell script action that is running a Python script. The Python script is using the markdown Python library to extract the Markdown meta data fields and values.
import markdown
import os
import sys
#This is where I want to search
filePath = "/Volumes/Macintosh HD/Users/weatherh/Dropbox/Notes"
## The tags to look for
matchTag = sys.argv[1:]
for fileName in os.listdir(filePath):
fileExtension = os.path.splitext(fileName)[1]
fullPath = filePath+"/"+fileName
# Exclude folders, hidden files and basically anything that is not a text file.
if os.path.isfile(fullPath) and not fileName.startswith('.') and fileExtension == '.txt':
myFile = open(fullPath, "r")
rawText = myFile.read()
myFile.close()
# Handle the odd characters. Just kill them.
rawText = rawText.decode('utf-8')
# Process with MD Extras and meta data support
md = markdown.Markdown(extensions = ['extra', 'meta'])
md.convert(rawText)
## extract the tags but keep them as a list
if hasattr(md, 'Meta'):
if 'tags' in md.Meta:
headerTags = md.Meta['tags']
# Only pass files that are a subset of the header tags
if set(matchTag).issubset(set(headerTags)):
print fullPath
The script is really just a modified version of the one in my original Hazel post. There's not too much new going on.
The script is easily extended to search other Markdown meta fields as well.
I'm not a huge fan of Automator, but for quickly adding some UI chrome to a Shell script, it's great. I really wish there was an easier way though. I use smart folders regularly and it's a shame they don't work with MultiMarkdown meta data.
For a simulated smart folder, use the "Reveal in Finder" Automator action instead of the file open action. It will open a Finder window and select the matching files.
This little project was part frustration and part exploration. I satisfied my need for exploration.
The Automator workflow file can be downloaded on GitHub.